If you're working in data science, you’ve likely realized by now that Linux isn’t just some background system—it’s the environment where most of your tools live. Python scripts, data pipelines, Jupyter notebooks, Docker containers, databases—you name it. To work with them smoothly, you need to speak Linux fluently enough to get through your day without stumbling.
That doesn’t mean mastering obscure flags or memorizing every single bash trick. But it does mean knowing your way around the terminal. Whether you’re managing large datasets, configuring environments, or troubleshooting code, these 10 commands are your baseline in 2025.
10 Basic Linux Commands for Data Science in 2025
ls – Listing What’s Around You
This is where everything begins. The ls command shows you what’s inside a folder, and it’s the most frequently used command in your day. It's not just about listing files, though. With options like ls -lh, you see sizes in human-readable form, which helps when you're scrolling through 15 CSVs and want to know which one’s taking up half your storage.
Throw in ls -lt to sort by last modified time or ls -la to check hidden files and folders (which often include environment files or .git directories). You're not just poking around. You're finding your way to that notebook or script you swore you saved yesterday.
cd – Moving Through the Maze
You’ll use cd so often that your muscle memory might know it better than your fingers do. It’s how you move from one directory to another, which is especially helpful when you’re bouncing between folders for code, raw data, and model outputs.
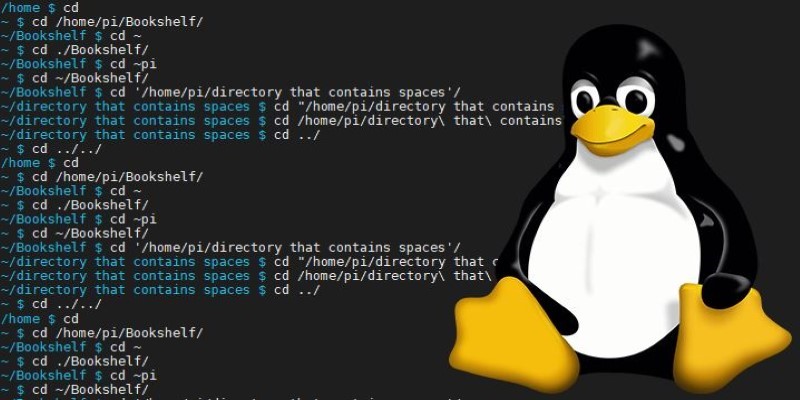
In 2025, with most data science setups split between local machines and mounted remote directories or containers, cd remains the fastest way to navigate. And with the addition of cd - to jump to your previous location, it saves time when you're flipping between folders without opening 10 new terminal windows.
pwd – Knowing Where You Are
Ever get lost in layers of nested folders and forget where you are? That’s where pwd steps in. It prints your current working directory. Useful when your command line prompt is customized to show only the time and username (or nothing at all), and you need a quick reality check.
This command matters more when you're working in environments like Docker containers or remote sessions over SSH, where folder structures aren’t always what you expect.
cp – Making Copies Without Fuss
Copying files is second nature, and cp is your go-to for it. Want to back up your cleaned dataset before testing a risky operation? cp data_clean.csv data_clean_backup.csv.
For entire folders—maybe you want to clone an experiment folder before tweaking parameters—cp -r handles recursive copying. It quietly becomes one of your safeguards against data loss or errors. No version control system is needed, just a quick duplicate for peace of mind.
mv – Moving or Renaming Without Extra Tools
mv pulls double duty. It moves files and also renames them. And both are pretty common in a data science workflow. Maybe you just downloaded a dataset from an API, and the file name is data_v2_final_really_final.csv—rename it to something that won’t annoy you later.
Or you’ve split your dataset and want to organize the parts: mv train.csv datasets/train/ does the job without clicking through folders. Clean workspace, clean mind.
rm – Getting Rid of the Unnecessary
Yes, you’ll use rm with caution. One wrong move and your notebook, logs, or even source files vanish. But once you get comfortable, it’s essential for clearing temporary outputs, failed model runs, and outdated logs.
Adding the -r flag allows you to remove folders, too, like rm -r temp_output/, which is great for cleaning up batch experiment directories that are no longer needed. No pop-ups, no recycle bin—just clean removal, which can be a relief in a cluttered directory.
head and tail – Peeking Into Files Without Opening Them
When you’re handed a massive dataset and want to take a quick look without opening it in pandas or Excel, head and tail are all you need. head data.csv gives you the first few lines. tail data.csv gives you the last.
They’re especially useful for log files, where you can run tail -f logs.txt to watch events as they happen in real time. This comes in handy when you're training a model and want to monitor its progress without interrupting the run.
grep – Searching Without the Noise
Think of grep as your quick-search for everything text-based. Want to find all lines in your code that reference a certain variable or keyword? grep 'learning_rate' train_model.py handles it.
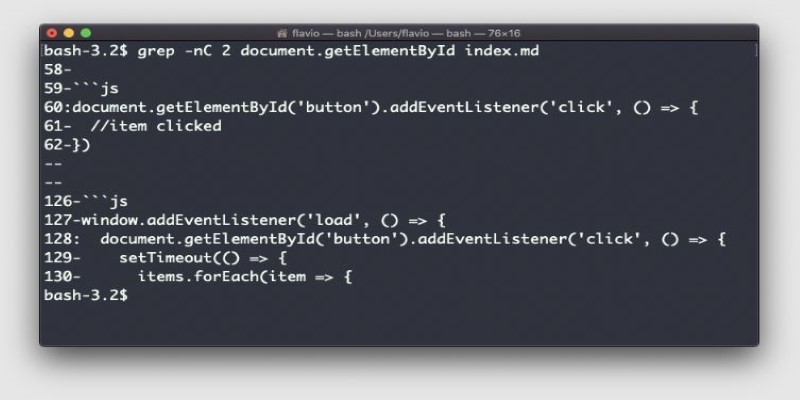
With larger log files, grep helps isolate issues without scrolling endlessly. You can even combine it with other commands: cat logs.txt | grep 'ERROR' filters out the clutter and gets straight to the point. And in multi-file searches, grep -r 'model.fit'. scans all files in a directory. No IDE needed.
find – Locating Files Like a Pro
Sometimes, you know the file name (or part of it), but you have no clue where it's hiding. find searches for it. A basic example: find. -name '*.csv' helps when you're tracking down that missing dataset from last week.
With large repositories, distributed datasets, and cloud-mounted folders becoming the norm, find becomes your behind-the-scenes assistant. Combine it with actions like -exec to do things to the files it locates—delete, move, or even grep within them.
chmod – Handling Permissions Without Headaches
In collaborative projects or when working with data stored in cloud buckets or on shared servers, permission issues pop up often. That’s where chmod comes in.
It lets you change who can read, write, or execute a file. For instance, chmod +x script.sh gives a script permission to run. It’s not glamorous, but it solves problems that can otherwise eat up an hour trying to debug a “command not found” or “permission denied” error.
This becomes even more relevant in 2025, as more workflows involve Docker, Kubernetes, and remote servers—where permission mismatches can halt your work instantly.
Conclusion
Even in 2025, these basic Linux commands stay relevant because they’re fast, dependable, and don’t rely on any interface to function. They work behind the scenes of the tools you already use and step in when those tools fall short. Whether you're troubleshooting, managing files, or scripting repeated tasks, this small set gives you control and speed. You don’t need to memorize hundreds—just use these well. They keep your workflow smooth, reduce friction, and help you stay focused on the actual work instead of getting lost in setup.